Comparing Open-Source Large Language Models to ChatGPT
Open-Source Large Language Models (LLMs) are remarkable for their community-powered evolution and open accessibility, leading to a robust platform for creative adaptation and innovation. In contrast, ChatGPT epitomizes the fruits of directed progress and dedicated optimization, providing an experience refined through intensive development and targeted objectives. This piece investigates the intricate contrasts between these methodologies, shedding light on how each fulfills unique needs within the artificial intelligence landscape and their contributions to evolving interactions between humans and computers.
Core Abilities
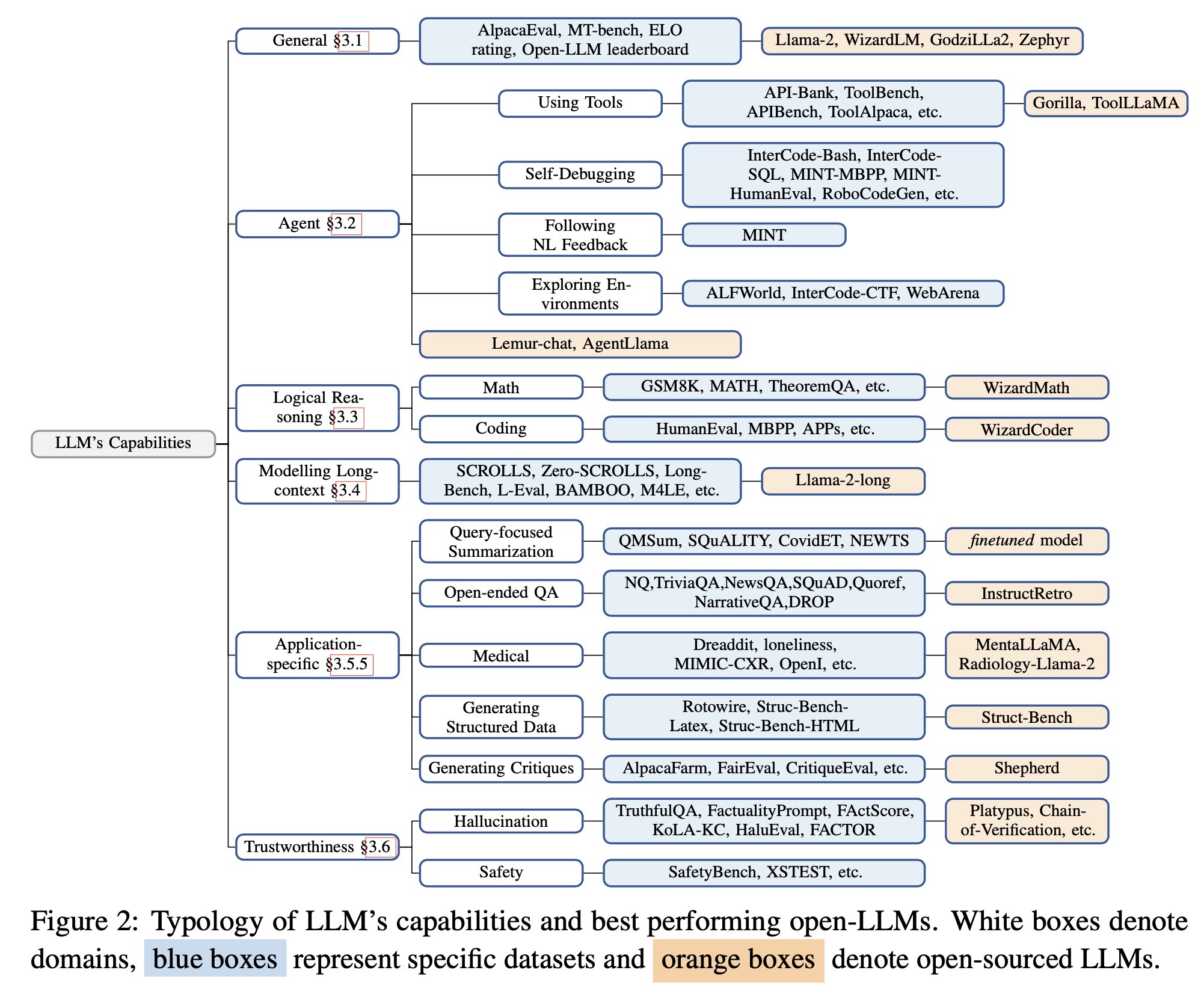
The Llama-2-chat-70B model demonstrates superior general conversation skills, outpacing the abilities of GPT-3.5-turbo; UltraLlama equates to GPT-3.5-turbo in designated benchmarks.
Capabilities in Practical Scenarios (utilization of tools, debugging itself, adhering to natural language instructions, environment exploration): The Lemur-70B-chat model surpasses GPT-3.5-turbo in environmental interaction and following coding guidelines in natural language. AgentLlama-70B shows parallel performance to GPT-3.5-turbo on novel agent-oriented tasks. Gorilla exceeds GPT-4 in generating API calls.
Logical Thought Processes
Specialized models such as WizardCoder and WizardMath, alongside models pre-trained on premium data sets (e.g., Lemur-70B-chat, Phi-1, Phi-1.5), exhibit enhanced results compared to GPT-3.5-turbo.
Handling Long-Context Information: Llama-2-long-chat-70B surpasses GPT-3.5-turbo-16k in ZeroSCROLLS evaluations.
Specific Application Proficiencies
- query-based summarization (superior with targeted training data)
- expansive QA (InstructRetro surpasses GPT3)
- healthcare (MentalLlama-chat-13 and Radiology-Llama-2 exceed ChatGPT)
- creation of structured outputs (Struc-Bench outshines ChatGPT)
- production of reviews (Shepherd nearly matches ChatGPT)
Reliable AI
Illusionary Outputs: improvement during fine-tuning – enhancing data quality; during prediction – utilizing specific strategies in decoding, augmenting with external knowledge sources (Chain-of-Knowledge, LLM-AUGMENTER, Knowledge Solver, CRITIC, Parametric Knowledge Guidance), and leveraging multi-agent dialogues.
Security Practices: The GPT-3.5-turbo and GPT-4 models are recognized for leading safety standards, largely through the application of Reinforcement Learning with Human Feedback (RLHF). Reinforcement Learning from AI Feedback (RLAIF) presents a potential for cost reduction in RLHF implementations.
Explore related articles:
OptiPrime – Global leading total performance marketing “mate” to drive businesses growth effectively. Elevate your business with our tailored digital marketing services. We blend innovative strategies and cutting-edge technology to target your audience effectively and drive impactful results. Our data-driven approach optimizes campaigns for maximum ROI.
Spanning across continents, OptiPrime’s footprint extends from the historic streets of Quebec, Canada to the dynamic heartbeat of Melbourne, Australia; from the innovative spirit of Aarhus, Denmark to the pulsating energy of Ho Chi Minh City, Vietnam. Whether boosting brand awareness or increasing sales, we’re here to guide your digital success. Begin your journey to new heights with us!